Monitor Virtuozzo Cluster Storage trên giao diện console của hardware node
Odin cung cấp 2 công cụ để monitor hệ thống cluster là thông qua web và command line.
Hôm nay chúng ta sẽ tiến hành monitor Cluster bằng command line thông qua lệnh ” pstorage -c cluster_name top ”
Lưu ý: Cluster_name là tên cluster của hệ thống.
#pstorage -c ods top
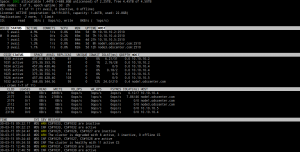
Bên trên là thông tin tổng quan về hệ thống cluster. Có thể chia ra thành 5 phần: tổng quan thông tin chung, MDS server, CS server, Client và Log của cluster.
Tiếp theo chúng ta sẽ phân tích sâu vào từng thành phần để nắm rõ về các thông số monitor cung cấp.
Phần 1: Tổng quan thông tin chung.
Ở phần này, monitor sẽ cung cấp cái nhìn tổng quan nhất về các thông số chung của cluster như: Name, Space cluster, số lượng MDS và CS, Replication, License, IO ….
| Tham Số | Mô Tả |
|---|---|
| Cluster | Tên của cluster. Lưu ý tình trạng Healthy, ở đây thể hiện Cluster hiện tại đang hoàn toàn ổn định. Vui lòng xem thêm về các thông báo trạng thái khác của cluster. |
| Space | Thể hiện dung lượng thật hiện có của cluster (VD: free 4.45TB of 4.50TB là tổng dung lượng toàn bộ các disk trong cluster), Allocatable 1.44TB (+688.9GB unlicensed) of 2.25TB: thể hiện dung lượng thật có thể sử dụng tối đa của cluster là 2.25TB. Tuy nhiên vì mới chỉ active license storage là 1.5TB nên cần phải mua thêm license ~700GB storage để có thể sử dụng hết 2.25TB. |
| MDS nodes | Số lượng MDS Nodes đã tạo trên cluster. |
| CS Nodes | Số lượng CS Nodes đã tạo trên cluster. |
| License | Tình trạng license,ngày hết hạn, cũng như dung lượng thật của license mà cluster có thể dùng. |
| Replication | Thông số Replication đang được cấu hình trên cluster. |
| Chunks | Các trạng thái chunk trên cluster (tính theo % tổng số chunk đang có trên cluster). Lưu ý các thông số như healthy,degraded,urgent,.. Ở đây tình trạng của healthy là 100% thể hiện tất cả các chunk đã được replication hoàn tất. |
| FS | Tổng dung lượng thật sự của các chunk trên cluster cũng như số lượng chunk replicas. |
| IO | Tốc độ thật về Input/Output của cluster. |
| IO Total | Tổng dung lượng đã đọc và ghi của cluster. |
| Repl IO | Tốc độ Replication của Cluster. |
| Sync rate và IO QDEPTH | Hai tham số này thể hiện tốc độ đồng bộ dữ liệu trên cluster cũng như tốc độ IO trung bình và cao nhất của cluster trong qúa trình hoạt động. |
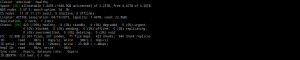
Phần 2 : MDS Server
Phần này sẽ tập trung vào các thông tin của các node MDS trên cluster.
![]()
| Tham Số | Mô Tả |
|---|---|
| MDS ID | Mỗi MDS khi tạo trên cluster đều có 1 ID riêng để xác định. Ký tự “M” trước ID MDS bất kỳ thể hiện MDS server đó là master MDS vì một thời điểm chỉ có 1 MDS đảm nhận Master còn lại đều là Slaver. |
| STATUS | Tình trạng hiện tại của MDS server (Avail thể hiện tình trạng MDS này đang hoạt động tốt) |
| %CTIME | Tổng lượng thời gian MDS server cần để ghi lên journal local. |
| COMMIT | Mỗi MDS đều có 1 ID riêng để xác định trên cluster. Ký tự “M” trước ID MDS bất kỳ thể hiện node MDS đó là master MDS. |
| %CPU | Lượng % CPU MDS đang sử dụng. |
| MEM | Lượng bộ nhớ RAM vật lý mà MDS đang sử dụng. |
| UPTIME | Tổng thời gian MDS đã online từ lần khởi động gần nhất. |
| HOST | Địa chỉ HOST của MDS. |
Phần 3: CS server

Đây là phần tổng quan về CS server, các tham số quan trọng trên hệ thống cluster. Lưu ý là có thể dung phím “i” để chuyển đến các tab thông tin chi tiết hơn về CS server.
| Tham Số | Mô Tả |
|---|---|
| CS ID | Mã ID duy nhất của mỗi CS trên cluster. |
| STATUS | Tình trạng hiện tại của CS. Các thông số chi tiết về CS có thể xem tại đây. |
| SPACE | Đây là dung lượng trống của tất cả các disk trên chunk server. |
| AVAIL | Tổng dung lượng có thể ghi trên từng disk. |
| REPLICAS | Tổng số lượng chunk đang được phân phát và lưu trên từng disk. |
| IOWAIL | Phần trăm lượng Input/Output trên từng disk. Lượng IO Wailt này nếu qúa cao sẽ ảnh hưởng đếnhiêu năng của node và cluster. (IOWAIT dao động liên tục từ 0 ~ 50% được xem là tình trạng tốt, nếu cao hơn thể hiện Chunk server này đang quá tải performance, cần thêm disk hoặc chunk server mới) |
| IOLAT | Thể hiện thời gian Trung bình/tối đa (tính theo milliseconds) mà CS cần để thực hiện xong 1 tiến trình I/O. (IOLAT trung bình trong khoảng 0 ~ 200 ms được xem là tình trạng tốt, nếu cao hơn thể hiện Chunk server này đang quá tải performance, cần thêm disk hoặc chunk server mới) |
| FLAGS | Đây là những cờ quan trọng xác định các CS đang ở trạng thái nào. Chi tiết có thể xem tại đây. J : cờ J thông báo là CS hiện tại đang sử dụng tính năng write journal. C: cờ này dùng để checksum data có bị chỉnh sửa bởi 1 phần mềm bên ngoài nào đó không ( bảo đảm tính toàn vẹn của data ) D: cờ này thể hiện CS đang sử dụng tốc độ I/O thật của nó. Không dùng write journal. c: cờ này thể hiện dung lượng hiện tại của journal hiện đang trống. Không có hoạt động nào tác động write journal nào từ SSD đến HDD nơi CS được đặt. |
Phần 4 : Client

Phần này cung cấp các thông tin về client trong cluster.
| Tham Số | Mô Tả |
|---|---|
| CL ID | Mã ID duy nhất của mỗi Client trên cluster. |
| LEASE | Số lượng file trung bình các file đã được mở dành cho qúa trình đọc ghi và số lượng các file hiện tại vừa được đóng. |
| READ | Tỉ lệ trung bình bao nhiêu byte dữ liệu client có thể đọc theo giây. |
| WRITE | Tỉ lệ trung bình bao nhiêu byte dữ liệu client có thể ghi theo giây. |
| RD_OPS | Trung bình thời gian client thực hiện một tiến trình đọc giây. |
| WR_OPS | Trung bình thời gian client thực hiện một tiến trình ghi theo giây. |
| FSYNCS | Trung bình thời gian client thực hiện 1 tiến trình đồng bộ theo giây. |
| IOLAT | Trung bình thời gian tính bằng miliseconds mà client cần để thực hiện hoàn tất một tiến trình I/O. |
| HOST | Tên hoặc IP của client. |
Phần 5: Event Log
Trong phần event log cung cấp log về các tiến trình đã và đang hoạt động trong hệ thống. Log là 1 phần rất quan trọng của hệ thống.
Doanh nghiệp quan tâm về giải pháp vui lòng liên hệ trực tiếp cho ODS theo số hotline (028) 7300 7788 hoặc website: https://ods.vn để được tư vấn và hỗ trợ nhanh nhất.

